
一、前言
Redis 是一款 key-value 内存数据库。由于其上手快,执行效率高,拥有多种数据结构,支持持久化以及集群等功能和特点被众多互联网公司所使用。但是,如果使用和操作不当,会引起内存浪费,甚至系统宕机等严重后果。
二、要点分析
2.1 使用正确的数据类型
在 Redis 5 种数据类型中,string 类型最为常用,也最为简单。但是,能解决问题不代表使用了正确的数据类型。
例如,将一个用户(name,age,city)信息保存到 Redis 中,下边有三种方案:
方案1:使用 string 类型,每个属性当作一个 key
1 | set user:1:name laowang |
1 | 优点:简单直观,每个属性支持更新操作 |
方案2:使用 string 类型,将用户信息序列化成字符串保存
1 | // 序列化用户信息 |
1 | 优点:简化存储步骤 |
方案3:使用 hash 类型,每个属性使用一对 field-value,但只用一个 key
1 | hmset user:1 name laowang age 40 city shanghai |
1 | 优点:简单直观,合理使用可以减少内存空间 |
总结:尽量减少 Redis 中的 key。
2.2 警惕 Big Key
big key 一般指的是字符串类型 value 值非常大(大于10KB),或哈希、列表、集合、有序集合元素个数多(大于5000个)的 key。
big key 会对 Redis 造成很多负面影响:
1 | 内存不均:在集群环境下,big key 被分配到某个节点机器中,由于不知道被分配到哪个节点上且该节点内存占用大,不利于集群环境下内存的统一管理 |
知道了 big key 的危害,我们如何判断和查询 big key 呢?其实,redis-cli 提供了 --bigkeys 参数,键入 redis-cli --bigkeys 即可查询出 big key 。
找到 big key 后,我们一般会将 big key 拆分成多个小 key 进行存储。这种做法似乎与 2.1 的总结相矛盾,但任何方案都有优缺点,衡量利弊取决于实际情况。
总结:尽量减少 Redis 中的 big key。
补充:如果想查看某个 key 所占用的内存空间,可以使用 memory usage 命令。注意:该命令是 Redis 4.0+ 才开始提供的,如想使用必须将 Redis 升级至 4.0+。
2.3 内存消耗
即便我们合适使用正确的数据类型保存数据,将 Big Key 拆分小 key,还是会出现内存消耗问题,那么 Redis 内存消耗是如何产生的呢?一般由以下 3 种情况产生:
1 | 业务不断发展,存储的数据不断增多(不可避免) |
在优化情况 2 之前,我们得先知道为什么会出现没有及时处理过期数据的问题,这得说到 Redis 提供的 3 种过期删除策略:
1 | 定时删除:对于每个设置了过期时间的 key 都会创建一个定时器,一旦达到过期时间就立即删除 |
由于定时删除需要创建定时器,会占用的大量内存,同时精准删除大量 key 也会消耗大量 CPU 资源,因此 Redis 同时采用的是惰性删除和定期删除两种策略。如果客户端没有请求过期的 key 或定期删除线程没有扫描到并清除这个 key,该 key 就会一直占用着内存,导致内存浪费。
知道了内存消耗的原因后,我们可以很快地想出优化方案:手动删除。
当使用完缓存后,缓存即使设置了过期时间,我们也要手动调用 del 方法/命令删除。如果不能当场删除,我们也可在代码中开启定时器定期删除这些过期的 key,相比较 Redis 的两种删除策略,手动清除数据要及时很多。
情况 3 的问题不算大,针对其优化的手段,我们可以调整 Redis 的淘汰策略。
2.4 多命令的执行
Redis 是基于一个 request, 一个 response 的同步请求服务。即当多个客户端向 Redis 服务端发送命令时,Redis 服务端只能接收和处理其中的一个客户端的命令,其他客户端只能等待 Redis 服务端处理好当前的命令并作出响应后才会继续接收和处理其他命令请求。
Redis 处理命令分 3 个过程:接收命令,处理命令,返回结果。由于处理的数据都是在内存中的,因此处理时长通常都是纳秒级别,非常快(big key 除外)。因此,大部分耗时的情况都发生在接受命令和返回结果上。当客户端发送多个命令给 Redis 服务器时,如果有一条命令处理时长很久,其他命令只能等待着,从而影响整体性能。
为了解决这类问题,Redis 提供了 pipeline(管道),客户端可以将多条命令放入 pipeline 中,然后一次性将 pipeline 的命令发给 Redis 服务端处理,当 Redis 服务端处理完毕后再一次性将结果返回给客户端。这样处理减少了客户端与 Redis 服务端的交互次数,从而减少了往返时间,提升了性能。
补充:
Redis pipeline 与原生批量命令对比:
1 | 原生批量命令是原子性,pipeline 是非原子性 |
使用 Redis pipeline 的注意事项:
1 | 使用 pipeline 装载的命令数量不能太多 |
2.5 缓存穿透
在项目中运用缓存,我们通常的设计思路如下图:
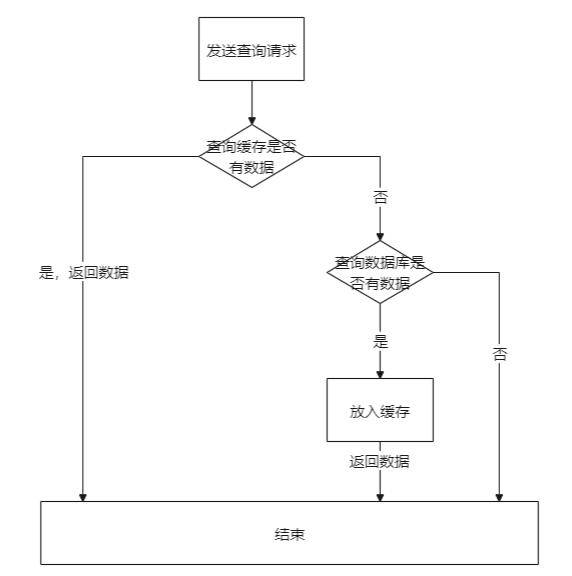
发送请求查询数据,查询规则是先查缓存,如果缓存没有数据再查询数据库,将查到的数据放入缓存最后返回数据给客户端。如果请求的数据是不存在的,最终每次请求都会请求到数据库中,这就是缓存穿透。
缓存穿透存到很大的安全隐患,如果有人使用工具发送大量请求,请求一个不存在的数据,大量请求会流入到数据库上,导致数据库压力增大,可能会导致数据库宕机,进而影响整个应用的正常运行,导致系统瘫痪。
解决这类问题,重点在于减少对数据库的访问,通常有以下几种方案:
1 | 缓存预热:系统发布上线后,提前把相关的数据直接加载到缓存系统中 |
2.6 缓存雪崩
缓存雪崩: 简单来说是指大量请求访问缓存数据但无法查询到,进而去请求数据库,导致数据库压力增大,性能下降,不堪重负宕机,从而影响整个系统正常运行,甚至系统瘫痪的现象。
比如,一个完整的系统由系统A,系统B,系统C 三个子系统组成,它们的数据请求链是系统A -> 系统B -> 系统C -> 数据库。如果缓存中没有数据,数据库宕机,系统C不能查询数据作出响应,只能处在重试等待的阶段,从而影响了系统B 和系统A。一处节点发生异常导致一连串的问题就像雪山的一阵风吹过引起雪崩的现象。
看到这里,可能有读者会疑惑,缓存穿透和缓存雪崩有什么区别呢?
1 | 缓存穿透侧重于请求的数据不在缓存中,从而去请求数据库,就好像直接透过缓存直接请求数据库。 |
要解决缓存雪崩问题,还是得先知道导致问题的原因:
1 | Redis 自身出现问题 |
针对原因1,我们可以做主从,集群,尽量让请求都在缓存中查到数据,减少对数据库的访问
针对原因2,给缓存设置过期时间时,错开过期时间(如在基础时间上在增减一个随机值),避免缓存集中失效。同时,我们还可以设置本地缓存(如 ehcache),对接口进行限流或服务降级,也可以减少数据库的访问压力。



